Socials section
About Me
I'm Eph Baum
I play make pretend as a software engineer. This is my blog where I talk to myself to answer my own questions about tech, engineering, and working with people.
Check out the blog →Made with using:
-
AI
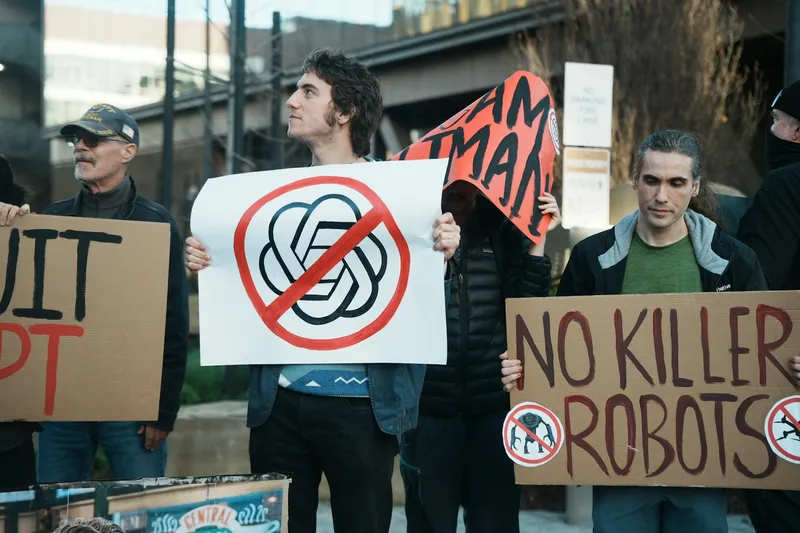
This may read as alarmist. It might not be alarmist enough. On AI as sophisticated autocomplete, not thinking—and why that gap matters to the future.
-
Slow Down

Speed worship is anxiety wearing a productivity costume. The case for slowing down—and why going fast is often how you screw everything up.
-
Making Brutalist Design Accessible: A Journey in WCAG AA Compliance
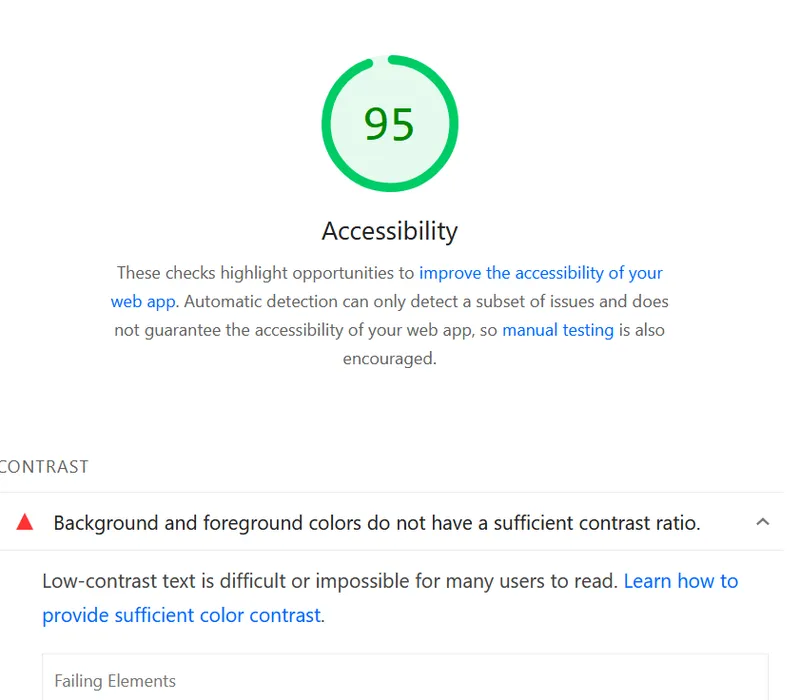
How I transformed my brutalist blog theme to meet WCAG AA accessibility standards while preserving its vibrant, random aesthetic. Talking about contrast ratios, color theory, and inclusive design.
-
Building Horror Movie Season: A Journey in AI-Augmented Development
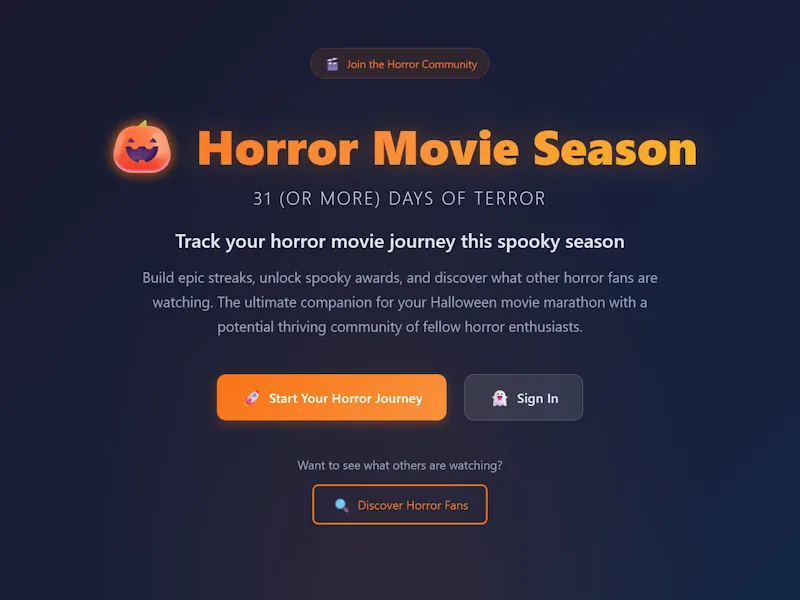
How I built a production web app primarily through 'vibe coding' with Claude, and what it taught me about the future of software development. A deep dive into AI-augmented development, the Horror Movie Season app, and reflections on the evolving role of engineers in the age of LLMs.
-
Chaos Engineering: Building Resiliency in Ourselves and Our Systems

Chaos Engineering isn't just about breaking systems — it's about building resilient teams, processes, and cultures. Learn how deliberate practice strengthens both technical and human architecture, and discover "Eph's Law": If a single engineer can bring down production, the failure isn't theirs — it's the process.
-
Using LLMs to Audit and Clean Up Your Codebase: A Real-World Example

How I used an LLM to systematically audit and remove 228 unused image files from my legacy dev blog repository, saving hours of manual work and demonstrating the practical value of AI-assisted development.